抖音运营
- 小红书下拉和抖音下拉框...
- 抖音下拉框搜索怎么做,...
- 年轻人啃老好还是创业好...
- 女生做抖音自媒体,真正...
- 想去字节抖音公司上班,...
- 2025年抖音电商怎么做,想...
- 有人要10万买你抖音账号,...
- 抖音还有精选版app,有没...
- 当抖音下拉框负面舆情后...
- 2025抖音流量变少了,原来...
- 抖音豆包发布视觉理解大...
- 2025抖音4种投流方式,看看...
- 现在不刷抖音短视频,你...
- 国产ai应用二次开发,算不...
- 抖音下拉宝说单独一个人...
- 现在电商刷单还有用吗,...
- 电商能干掉理发店吗,理...
- 抖音无货源店铺如何选品...
- 2024抖音点赞千万视频,想...
- 抖音千川粉是不是有效粉...
抖音豆包发布视觉理解大模型,看到就理解!
发布时间:2025-02-10 14:14
这几天,AI的疯狂突破让全球科技圈炸开了锅,Open AI让AI已经能听、能看,还能动手做事,谷歌更是带来了多模态交互的新高度。但让人振奋的是,国内的AI力量也交出了自己的答卷。
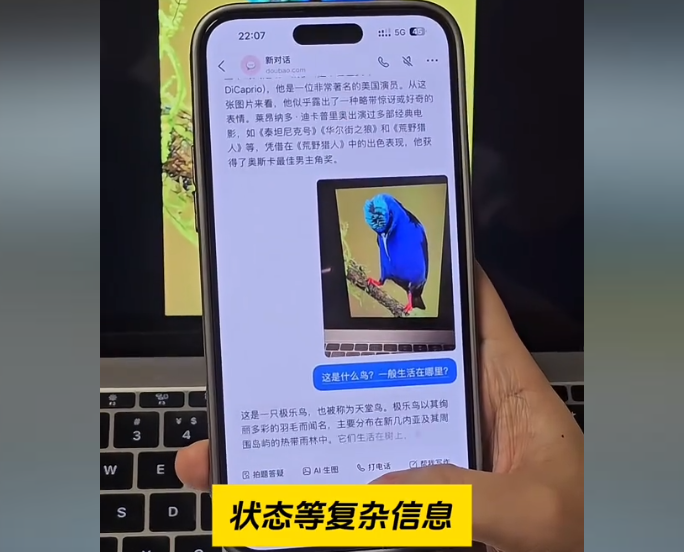
抖音豆包视觉理解大模型重磅也发布了,豆包的进步速度真的太快了,不仅实现了语言、视觉、音乐、交互等领域的全面升级,从基础能力到应用场景都展现出扎实的技术积累。不得不说,这次发布的视觉理解大模型真的强,任意一张图片,豆包都能秒识别动作、情绪、位置、状态等复杂信息,还能轻松理解中国传统文化,AI的眼睛终于可以看懂我们的世界了,更令人兴奋的是,他还在数学逻辑和代码推理能力上有了突破,解数学题指出代码错误,给出修改方案。以后父母可以给孩子轻松。
讲题普通人也可以变身为程序员。抖音豆包的进步不只会看它,还能根据图片内容生成丰富的文字,比如产品介绍文章甚至视频脚本。它的视觉描述能力特别细腻,能够给教育、营销、电商等领域带来很多全新的可能。相比国外的产品,豆包的表现让看到了国内AI更懂我们国人的需求,最重要的是每个公司都用得起大模型。
此外,抖音豆包还发布了全新的3D生成模型,可以一键生成物理世界仿真模拟器,给机器人和原宇宙提供了基础世界。豆包大模型的升级,不仅技术上让人眼前一亮,更重要的是它以一种更开放的方式降低了企业接入的门槛,通过火山引擎,企业能以超低成本和门槛接入多模态交互能力,让曾经需要大团队、大预算的AI技术,现在中小企业也能轻松用上,这对整个行业来说意义非常重大
AI多模态时代真的到来了。过去我们总觉得多模态技术还很遥远,但抖音豆包用仅仅几个月就告诉我们,未来真的已经近在眼前。未来10年一定是AI的10年,你对多模态时代期待吗?
抖音豆包视觉理解大模型重磅也发布了,豆包的进步速度真的太快了,不仅实现了语言、视觉、音乐、交互等领域的全面升级,从基础能力到应用场景都展现出扎实的技术积累。不得不说,这次发布的视觉理解大模型真的强,任意一张图片,豆包都能秒识别动作、情绪、位置、状态等复杂信息,还能轻松理解中国传统文化,AI的眼睛终于可以看懂我们的世界了,更令人兴奋的是,他还在数学逻辑和代码推理能力上有了突破,解数学题指出代码错误,给出修改方案。以后父母可以给孩子轻松。
讲题普通人也可以变身为程序员。抖音豆包的进步不只会看它,还能根据图片内容生成丰富的文字,比如产品介绍文章甚至视频脚本。它的视觉描述能力特别细腻,能够给教育、营销、电商等领域带来很多全新的可能。相比国外的产品,豆包的表现让看到了国内AI更懂我们国人的需求,最重要的是每个公司都用得起大模型。
此外,抖音豆包还发布了全新的3D生成模型,可以一键生成物理世界仿真模拟器,给机器人和原宇宙提供了基础世界。豆包大模型的升级,不仅技术上让人眼前一亮,更重要的是它以一种更开放的方式降低了企业接入的门槛,通过火山引擎,企业能以超低成本和门槛接入多模态交互能力,让曾经需要大团队、大预算的AI技术,现在中小企业也能轻松用上,这对整个行业来说意义非常重大
AI多模态时代真的到来了。过去我们总觉得多模态技术还很遥远,但抖音豆包用仅仅几个月就告诉我们,未来真的已经近在眼前。未来10年一定是AI的10年,你对多模态时代期待吗?